Hadoop
Hadoop
Hadoop
Hadoop 概述
Hadoop 特点
- 稳定性
多台机器集群,部分机器故障时,剩余机器仍可对外服务 - 高效性
多台机器一起运算 - 高扩展性
可以不断往集群中添加机器 - 低成本性
普通 PC 的集群
大数据-物联网-云计算三者之间的关系?
两大核心
HDFS
海量数据的存储
MapReduce
海量数据的处理
各个组件
- MapReduce
基于磁盘 - Spark
基于内存 - Hive
Hadoop 上的数据仓库
将 SQL 语句转成 MapReduce 作业 - Pig
- Oozie
Hadoop 上的工作流管理系统 - Zookeeper
提供分布式协调一致性服务 - HBase
Hadoop 上的非关系型的分布式数据库
Hadoop 集群的部署
Hadoop 分为 HDFS 和 MapReduce
MapReduce 分为 JobTracker 和 TaskTracker
HDFS 典型拓扑
集群硬件配置
DataNode/TaskTracker 的硬件规格方案:
- 4 个磁盘驱动器(单盘 1-2 T),支持JBOD
- 2 个 4 核 CPU,至少 2-2.5 GHz
- 16-24 GB 内存
- 千兆以太网
NameNode 的硬件规格方案:
- 内存: 16-72 G
- 内存通道优化
- 2-8 核 CPU
- 万兆网络
管理各种元数据并提供服务
很多元数据直接保存在内存中
集群规模
节点数量
Hadoop集群规模可大可小,初始时,可以从一个较小规模的集群开始,比如包含10个节点,然后,规模随着存储器和计算需求的扩大而扩大
存储大小
如果数据每周增大1TB,并且有三个HDFS副本,然后每周需要一个额外的3TB作为原始数据存储,要允许一些中间文件和日志(假定30%)的空间,由此,可以算出每周大约需要增加一台新机器存储两年数据的集群,大约需要100台机器
现有2000人,每人需要1.2M 空间存储数据,请问在HDFS 系统中,需要多大的存储空间存储上述人员的数据?(需要说明原因,仅给出计算式仅得答案分)(10 分)
每个人需要1.2MB的空间,那么2000人总共需要的存储空间为:
2000×1.2MB=2400MB=2.4GB
在HDFS中,默认情况下每个文件会被分割成块(block),并且会创建多个副本(默认是3副本)。因此,实际需要的存储空间还要乘以副本数量,即:
2.4GB×3=7.2GB
其他
对于一个小的集群,名称节点(NameNode)和JobTracker运行在单个节点上,通常是可以接受的。但随着集群和存储在HDFS中的文件数量的增加,名称节点需要更多的主存时,名称节点和JobTracker就需要运行在不同的节点上
第二名称节点(SocondaryNameNode)会和名称节点可以运行在相同的机器上,但是,由于第二名称节点和名称节点几乎具有相同的主存需求,因此,二者最好运行在不同节点上
大数据通常指的是“4V”特性:Volume(大量)、Velocity(高速)、Variety(多样)、Veracity(真实性)。
大数据的发展离不开信息化浪潮,我们现在正在经历第( C)次信息化浪潮。
A.一B.二C.三D.四
我们当前正经历第三次信息化浪潮,以下哪种技术不属于第三次信息化浪潮的关键技术( A )? A. 人工智能B.大数据C.云计算D.物联网
HDFS
请画出 HDFS 节点部署典型拓扑结构示意图,并以此为基础说明该拓扑结构的的优点与缺点?
HDFS的典型拓扑结构包含NameNode(管理文件系统元数据)、Secondary NameNode(辅助NameNode进行检查点操作)和多个DataNode(存储实际数据块)。
优点包括高容错性和可扩展性
缺点可能是单点故障(已被HDFS HA解决),以及对网络带宽的要求较高。
优点:高容错性、兼容廉价的硬件设备、流数据读写、适用大数据集、简单的文件模型、强大的跨平台兼容性
缺点:不适合低延迟数据访问、无法高效存储大量小文件、不支持多用户写入及任意修改文件
HDFS 的体系结构是什么?并基于其体系说明读写数据的流程是什么?(10 分)



写数据流程:
- 客户端请求:客户端向NameNode请求写入文件。
- 分配块:NameNode根据文件大小和块大小,决定需要多少块来存储文件,并为这些块分配存储位置。
- 数据传输:客户端根据NameNode的指示,将文件数据写入指定的DataNode。这个过程是并行的,客户端会同时向多个DataNode发送数据块。
- 确认写入:DataNode在接收到数据后,会向NameNode发送确认信息。
- 元数据更新:NameNode在接收到所有DataNode的确认后,更新文件系统的元数据。
读数据流程:
- 客户端请求:客户端向NameNode请求读取文件。
- 获取块信息:NameNode返回文件块的位置信息。
- 数据传输:客户端根据NameNode提供的块位置信息,直接从DataNode读取数据块。
- 数据合并:如果文件被分割成多个块,客户端会将这些块合并,以恢复原始文件。
- 缓存:客户端可能会将读取的数据缓存起来,以提高后续访问的速度。
HDFS HA
HDFS HA工作机制简述
HDFS HA通过配置一对Active和Standby NameNode来工作。Active NN处理所有客户端请求,而Standby NN同步Active NN的状态,准备接管。如果Active NN发生故障,Standby NN会迅速切换成Active状态,继续提供服务,保证业务连续性。
在HDFS2.0 中提出了HDFS HA,其主要解决的是什么问题?( C )。
A.负载均衡问题B.内存优化问题C.单点失效问题D.隔离问题
在HDFS2.0 中提出了( C ),其主要解决的单点失效的问题。
A.Pig B.HDFS F
C.HDFS HA D.MLLib
HDFS HA 是热备份,提供高可用性,但是为什么无法解决可扩展性、系统性能和隔离性?
HDFS HA主要解决的是高可用性问题,即确保当主NameNode发生故障时有备用节点可以接管服务。然而,它并不直接涉及集群的可扩展性(可以通过增加DataNode来实现)、系统性能优化(需考虑如负载均衡等其他方面)和多租户环境下的资源隔离(可能需要额外的策略或工具来实施)。
尽管HDFS HA通过引入备用NameNode实现了主节点故障转移,提高了系统的可用性,但它并没有改变单个NameNode管理整个命名空间的事实,因此对于大规模集群来说,仍然存在单一瓶颈的问题,影响了系统的整体可扩展性和性能。另外,HA架构下的两个NameNode共享相同的命名空间,不能实现完全的服务隔离。
MapReduce
MapReduce适合处理离线批处理任务的原因
MapReduce通过将一个大型计算任务分解为多个独立的子任务(Map阶段),然后汇总这些子任务的结果(Reduce阶段)来完成。由于它的工作流程包括数据读取、映射、洗牌与排序、减少和输出,这使得它非常适合处理大量数据的离线批处理任务。每个步骤都是在不同节点上并行执行的,能够有效利用集群资源,并且对容错性有很好的支持,可以重新运行失败的任务。
Other
MapReduce 中,体现了(B )的理念。
A.数据向节点靠拢B.计算向数据靠拢
C.数据向计算靠拢D.数据分批处理
Hadoop 中MapReduce 模块是基于(C )的计算。
A.CPU B.内存C.磁盘D.GPU
Hadoop 中,MapReduce 是负责计算的模块,请问MapReduce 中管理节点的名称为( A )。
A.JobTracker B.NameNode
C.JobNode D.TaskTracker
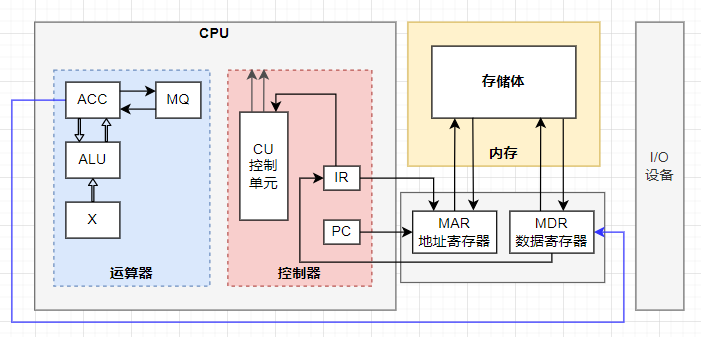
MapReduce 的体系结构是什么?以及如何执行任务的?请简要说明。

MapReduce执行的全过程包括以下几个主要阶段:从分布式文件系统读入数据、执行Map任务输出中间结果、通过 Shuffle阶段把中间结果分区排序整理后发送给Reduce任务、执行Reduce任务得到最终结果并写入分布式文件系统。
下图展示了一个WordCount 程序的示意图,请根据MapReduce 原理填空(对应章节ppt里面仔细复习)
HBase
HBase 是一个稀疏、多维度、排序的映射表,其是一种面向列的存储,其能够更好的解决(C)型事务性任务。
A.问题B.分析C.查询D.列举
请从HBase的存储模式,说明HBase的优点?
HBase采用列族存储模型,这种模型允许高效的随机读写操作,因为它能快速定位到特定的行键和列族。此外,它支持版本化数据,可保存多个时间戳的数据副本,有助于历史数据分析。HBase还提供了自动分片功能,即根据数据量增长自动分裂表,确保良好的扩展性和性能。
Hive
Hive与传统数据库的区别:
Hive是建立在Hadoop之上的数据仓库工具,设计用于处理大规模静态数据集,它使用类似于SQL的语言——HQL,但不像传统关系型数据库那样支持事务、索引等特性。Hive更适合于批量数据处理和分析,而不是实时查询或频繁更新的操作。
请简要论述Hive与传统数据库的区别?
数据插入:传统数据库中同时支持导入单条数据和批量数据,而Hive中仅支持批量导入数据。 数据更新:Hive不支持数据更新,存放的是静态数据。传统数据库支持数据更新。 查询语言:Hive使用HQL,传统数据库使用SQL。 索引:Hive不像传统的关系型数据库那样有键的概念,它只提供有限的索引功能。 分区:传统的数据库分区是为了提高可管理性和数据库效率。Hive分区是为了加快数据的查询速度。 执行延迟: Hive的延迟比较高。 扩展性:传统数据库扩展性有限。Hive具有较好的可扩展性。 实时性:Hive:不适合实时查询,因为其设计是为了批量处理。传统数据库:支持实时查询。
spark
Spark运行架构的特点:
Spark具有内存计算能力,可以在内存中缓存中间结果,减少了磁盘I/O开销,提升了迭代算法的效率。它采用了一种叫做弹性分布式数据集(RDD)的抽象,支持多种语言接口,如Scala、Java、Python等,并且拥有丰富的库支持机器学习、图计算等功能。
Spark 能够有效解决( A )计算。
A.迭代B.离线批处理C.离线分析D.离线
请简要论述Spark运行架构的特点?
- 每个Application都有自己专属的Executor进程,并且该进程在Application运行期间一直驻留。Executor进程以多线程的方式运行Task
- Spark运行过程与资源管理器无关,只要能够获取Executor进程并保持通信即可
- Task采用了数据本地性和推测执行等优化机制
RDD的特点
RDD(Resilient Distributed Dataset)是Spark的核心抽象,表示不可变的、分区的记录集合。RDD具有以下特点: 容错性:通过血缘关系(lineage)重建丢失的数据; 分区性:数据被划分成多个分区,可在集群节点间并行处理; 懒加载:只有当动作操作触发时才会真正计算; 支持持久化:可以选择将RDD缓存在内存或磁盘上,以加速后续重复使用。
Stream
Related notes
- 所属 MOC: 学科知识MOC